Vorher lesen: Gesichert und verschwunden!
Files, Streams und Maps
Jetzt dass das Ausmaß des Desasters bekannt ist, kann die Rettung begonnen werden. Dafür werde ich keinen Plan machen, sondern Schritt für Schritt vorgehen.
- Die Liste aller vermissten Bilder, oder besser gesagt 300 davon, habe ich schon.
- Ich werde also versuchen, diese Bilder in meiner Ablage (NAS) zu finden. Die Bilder sind dort chronologisch sortiert in Unterverzeichnissen: es wird eine rekursive Methode brauchen. Der NAS ist über Samba-Mount an dem Mac angebunden, ich kann also direkt darauf zugreifen. Dann probiere ich es schon mal mit Brute-Force.
Die Idee ist einfach:
- aus meiner ersten Liste werden die Dateinamen extrahiert, dafür nehme ich reguläre Ausdrücke und dotNet Core hat dafür alle Methoden parat.
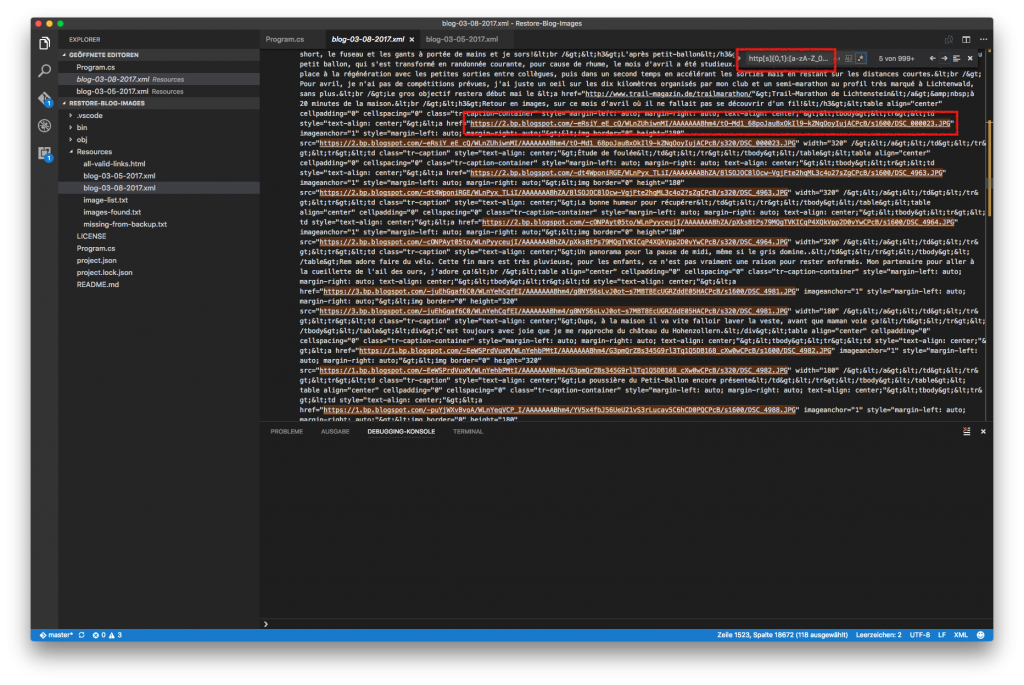
Mit der Suche von VS-Code lassen sich in Echtzeit die regulären Ausdrücke validieren, feine Sache - Diese Dateiname- Liste als Parameter übergeben, und rekursiv alle Verzeichnisse durchsuchen, dabei jedes Mal mit dem Verzeichnis Inhalt vergleichen.
- Ergebnisse werde ich in einer Tabelle sammeln (Key=Dateiname, Value=Pfad dahin) speichern.

Ich bin kein C# Spezialist, aber bis auf den Hashtable, (der „Dictionary“ heißt) findet man sich schnell zurecht. Das Einzige, was ich vermisse, ist ein automatischer Vorschlag für import („using“ in c#). Ist aber verschmerzbar.
VS Code macht dabei eine echt gute Figur, schlägt mir nach 2 bis 3 Buchstaben den richtige Begriff vor, so dass ich ich sogar schneller bin, als ich mit copy&paste wäre, wie man es vom Handy eigentlich gewohnt ist.
Bein Ausführen ist es auch noch sehr schnell.
270 von 300 Bilder habe ich wieder finden können. Ist schon ein guter Anfang!
- Bilder nach Google zurück schicken: die gefundenen Bilder muss ich jetzt wieder in der Cloud speichern. Dafür nutze ich einfach das Web-Frontend von Google-Photos, per drag and drop, ganz ohne Stress.
- Für die Freigabe im Blog braucht aber Google kryptisch Links zu den Bildern.

Diese Links kann ich nur beziehen, wenn ich die neu importierten Bilder in einen Post einbaue. Alles kein Problem, ich erstelle einen Post mit den 270 Bildern, die ich frisch importiert habe. Es sind schon ein paar Perlen dabei - Jetzt muss ich in alle Posts, alle falschen toten Links korrigieren. Ich probiere es kurz manuell und merke dass es keinen Wert hat! … Und jetzt?
Backup it!
Wie komme ich am besten an den Inhalt all meiner Blogs? Crawler? WGET? Wieder das gleiche Problem, wie am Anfang. Irgendwann, nach einer kleinen Jogging Runde, komme ich auf die Idee, dass ein Backup helfen könnte. Gibt es überhaupt eine Backup Funktion im Blogger? Warum habe ich nie ein Backup gemacht? Wie konnte ich so doof sein?
Viele interessante Fragen, aber auch Antworten! In der Tat, bietet Blogger eine Backup Funktion, leider nicht für Bilder, aber die Textinhalte lassen sich auf einen Schlag in einer XML-Datei exportieren, und wieder importieren!
Mehr brauche ich nicht, um weiter vorwärts kommen zu können!
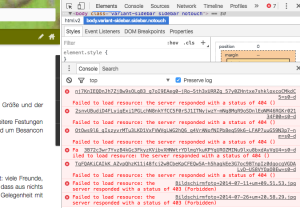
- Aus der Backup-Datei muss ich noch alle toten Links ermitteln, dafür kann mein Skript eine Verbindung aller Links erstellen und dabei erfahre ich, ob das Bild vorhanden ist oder. Dabei habe ich sogar einen Schritt mehr automatisiert!
- VS Code und ausgefeilte reguläre Ausdrücke helfen, um in der XML-Datei die toten Links durch korrekte Links zu ersetzen.
- Dabei musste ich noch berücksichtigen, dass die Bilder in verschiedenen Größen angezeigt werden und dass diese Größe URL kodiert ist.
- Die Spannung steigt und als ich meine korrigierte Backup-Datei zurückspiele, kann ich mich richtig freuen! Die 270 Bilder sind wieder da!
Restarbeit
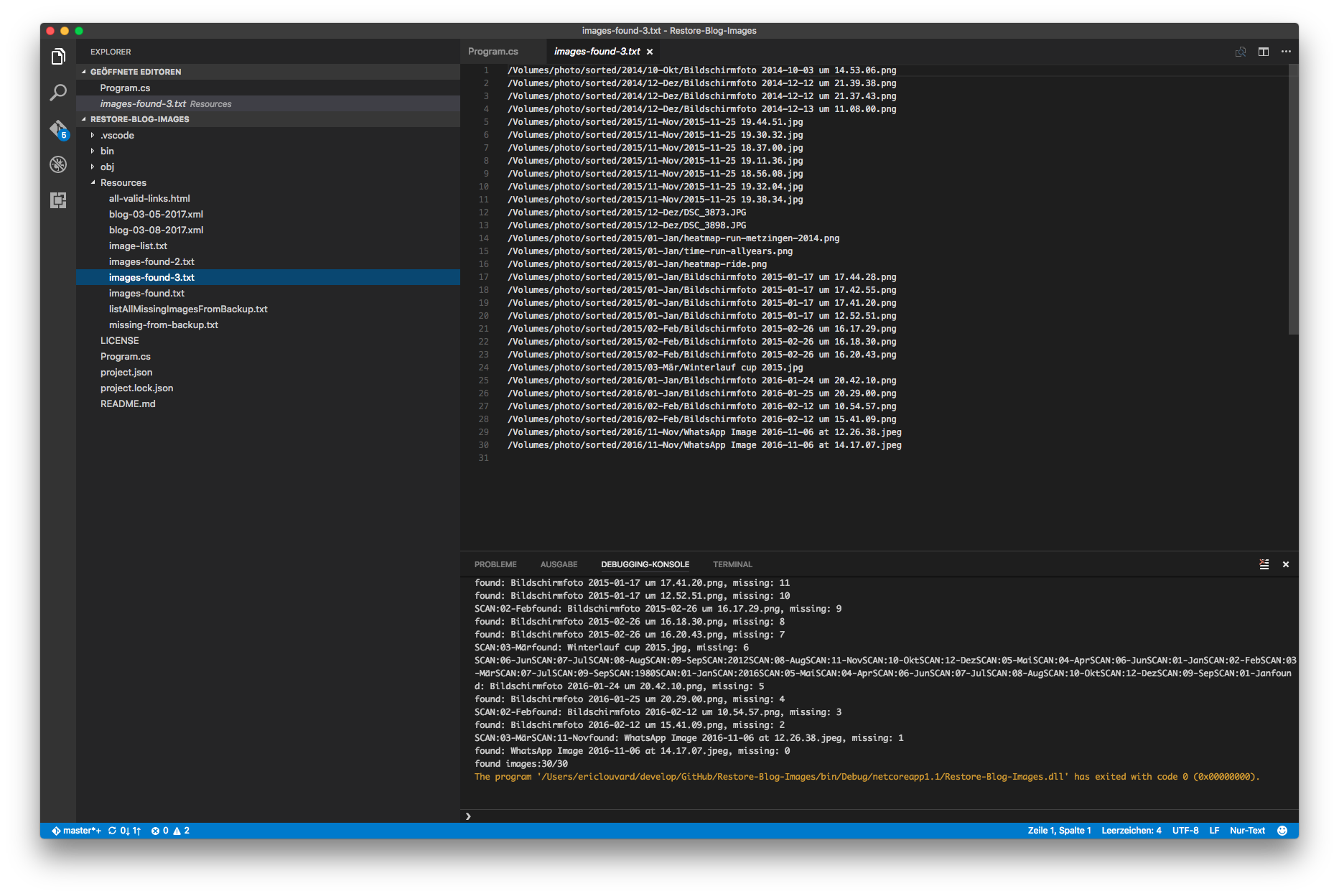
Jetzt bleibt zu klären, warum noch 30 Bilder vermisst werden, nach einer tieferen Analyse kommt folgendes heraus:
- Es gibt nicht nur „.jpg“, aber auch „.jpeg“ und „.png“ Bilder
- Bilder mit Leerzeichen werden nicht korrekt gefunden (die Menschheit wird autonom fahren, bevor die Informatiker ohne Leerzeichen Problematik leben können)
Beide Probleme können mit angepasstem regulär Ausdruck und URL-Unescape gelöst werden.
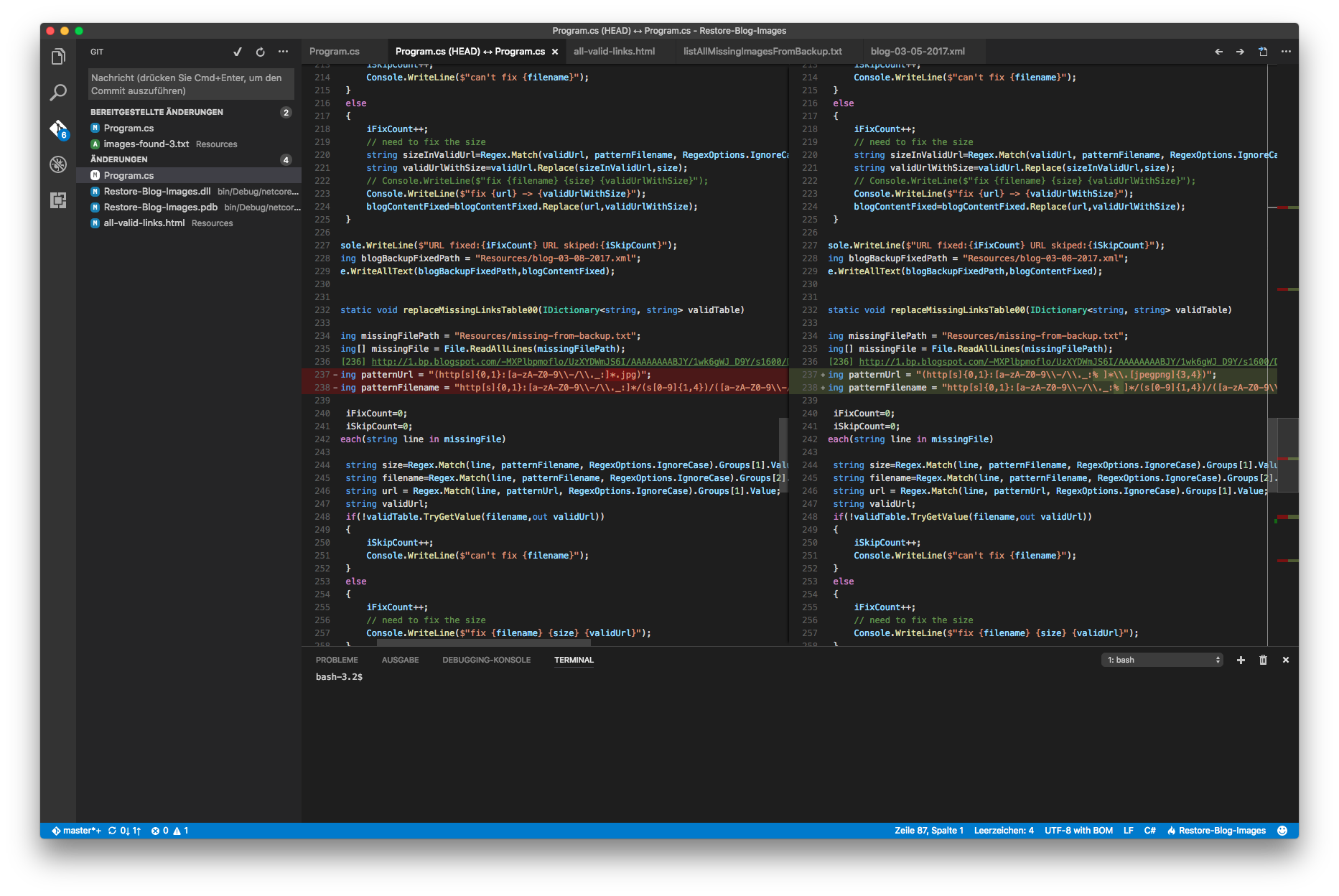
Nochmal alles laufen lassen:
- Aus der Backup Datei alle falsch verlinkten Bilder suchen
- Dateiname in der Ablage suchen
- Bilder in Google importieren und im Auflistungs Post hinzufügen
- Neue Bilder-Links in der XML Datei austauschen
- Alle Posts löschen (!)
- Einmal Gänsehaut bekommen und korrigierte Backup-Datei importieren
Ja! Alle Bilder sind da! Was für eine Freude!
Fazit
Wer kein Backup macht, geht davon aus aus, dass die Daten temporär gelagert sind und gibt den Daten kein Wert. Das weiß ich, und ich hatte unterschätzt, wie einfach die Bilder weggehen können. Hatte gedacht, dass google alles für mich zwei Mal absichert, ohne mir wirklich Gedanken darüber gemacht zu haben.
Es war ein langer Weg, aber dabei konnte ich bei jeder Etappe etwas lernen, dafür war es mir den ganze Umstand wert!
Mein Blog hat, für mich, an Wert gewonnen und ich konnte feststellen, wie wichtig es ist, für mich meine Erfahrungen zusammen zu fassen.
Visual Studio Code und dotNet Core sehen vielversprechend aus, und für einen IT Spezialisten, der 16 Jahre lang gern ohne Microsoft Technologie bestens zurecht gekommen ist, ist es ein Kompliment an Microsoft.
Der gesamte code kann in GitHub gelesen werden.
Danke für’s Lesen und bis bald,
Éric
PS: Backup nicht vergessen!